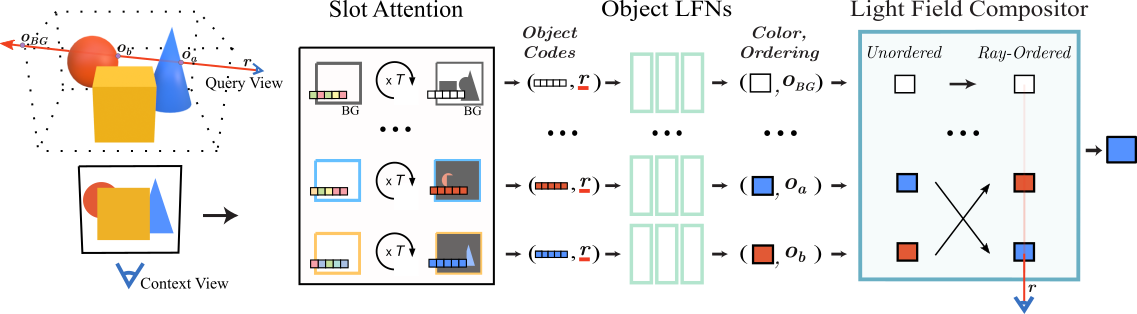
Neural scene representations, both continuous and discrete, have recently emerged as a powerful new paradigm for 3D scene understanding. Recent efforts have tackled unsupervised discovery of object-centric neural scene representations. However, the high cost of ray-marching, exacerbated by the fact that each object representation has to be ray-marched separately, leads to insufficiently sampled radiance fields and thus, noisy renderings, poor framerates, and high memory and time complexity during training and rendering. Here, we propose to represent objects in an object-centric, compositional scene representation as light fields. We propose a novel light field compositor module that enables reconstructing the global light field from a set of object-centric light fields. Dubbed Compositional Object Light Fields (COLF), our method enables unsupervised learning of object-centric neural scene representations, state-of-the-art reconstruction and novel view synthesis performance on standard datasets, and rendering and training speeds at orders of magnitude faster than existing 3D approaches.
TL;DR We combine slot attention and light field networks to
yield a 3D-aware, object-centric model without prohibitive memory
constraints.
Scene Decomposition
From a single view of a scene, our model infers a 3D description for each object and reconstructs the scene from a novel pose. We visualize novel views of each scene and its per-object contributions. Per-object contributions shown here are masked by their segmentation weight against the background slot.
Scene Editing: Cross-Scene Composition
Below, we demonstrate the advantage of using a light-field decoder in a cross-scene composition application, where we combine object latents from ten different scenes into a single scene with twenty objects. Prior object-centric, 3D-aware models are unable to represent scenes with such depth range and number of objects due to prohibitive memory constraints. The scene reconstruction and its per-object contributions are displayed below.
Scene Editing: Object Manipulation
We demonstrate a scene editing application of editing the scene on a per-object scale. For each scene, its objects are deleted sequentially (left), an object is centered (middle), and an object is orbited about the centered object (right).
Paper
